One key component in the development and evaluation of such a resilient system is having ability to simulate faults in controlled manner.
Chaos engineering is basically about empirically studying the system, simulating chaos, evaluating system resilience and building confidence in system capability to withstand real-world turbulent conditions.
Many developers don't distinguish between faults, errors and failures but otherwise this distinction is fundamental to engineering chaos in a distributed system. A fault is a defect that exists in a service but may be "active" or "dormant". An error occurs when fault becomes active. A failure occurs when the error is not suppressed and becomes visible outside the service.
 |
| Pathology of a Failure |
Faults, Errors and Failures....
A good understanding of faults is highly useful in engineering chaos. Following is one way to summarize the elementary fault groups that can affect a distributed system during its life time. These elementary fault groups can be further classified depending on the system at hand. For example, Software Faults is one elementary fault group. It can be further classified into Timing/Serialization faults, Algorithm faults, Validation faults, Design faults, Config faults etc.
 |
| Faults Classification |
These faults typically originate from one of the below 3 overlapping groups :
- Development faults i.e., faults that occur during development
- Environmental faults i.e., faults that occur due to hardware etc
- Operation faults i.e., faults that occur during interaction of services/components.
Below is a more detailed view on the relation between the fault origins and elementary fault groups.
 |
| Fault Origins |
For readers interested in understanding more details about the faults, following is a good paper - "Basic concepts and taxonomy of dependable and secure computing." Next we deal with errors.
Errors are part of the system state that can potentially lead to failures. We have two types of errors -detected errors and latent errors (i.e., errors that cannot be detected). Similarly some errors are single while others are correlated. Following are some broad categories of errors. This is certainly not an exhaustive list.
 |
| Types of Errors |
Failures happen when the errors surface. One key aspect to remember is, a system generally does not always fail in the same way. Typically failures can be characterized according to 3 view points -
- Consequences on the environment
- Domain and
- Perception by the users
From consequences on the environment viewpoint, failures can be typically categorized by severity i.e., benign failures and catastrophic failures.
Similarly from failure domain view point, the failures can be categorized as content failures (i.e., value delivered by the service is different from the expected), timing failures, authentication failures, performance failures, computation failures, crash failures, byzantine failures, omission failures (i.e., some results take too long while other requests go thru), configuration failures etc.
Similarly from failure perception view point, the failures can be typically categorized as consistent failures, inconsistent failures, data failures, detectable failures, load failures etc.
 |
| Failure Classes |
Means to Achieve Dependability...
So given all the above threats i.e., faults, errors and failures, how can we make our distributed system resilient and dependable? Following image is a good summary of various means available to a designer build dependability into the system -
 |
| Means to Achieve Dependability |
Various means to achieve dependability is covered fairly well else where and in references. So I will not dive deeper on the above in this post.
Now a system needs good fault tolerance capability to handle chaos. Following two images shed more light on the fault tolerance aspect i.e., techniques and strategies. If interested, good to read one of the fault tolerance papers mentioned in the references. If you are time constrained, go for the paper titled "Challenging malicious inputs with Fault Tolerance Techniques".
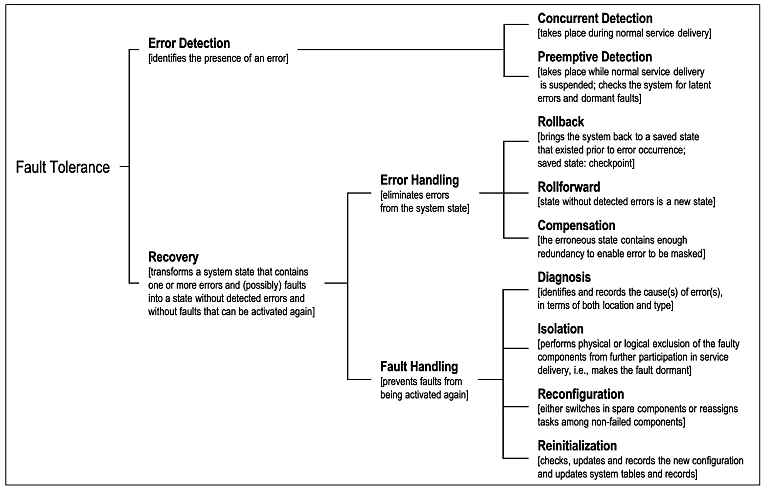 |
| Fault Tolerance Techniques |

We covered fairly broad ground quickly without going into details so that we can come quicker to chaos engineering part. Just one last image before diving into chaos engineering specifics.
Following image summarizes one design paradigm to integrate all of the above concepts into a coherent way. Just remember though...building systems in real world is a much messy process and iterative in nature. Nevertheless, below is a useful mental model to have.

Architecture of Chaos Engineering Service...
In my opinion, background knowledge on the concepts covered so far in this post will help one to design well and leverage chaos engineering. Following are some criteria to consider for building a chaos engineering service -
- Simplicity i.e., service is easy to setup, easy to define and add failure injections, detection and analysis. Preferably provide a REST based interface.
- Versatile i.e., framework support multiple types of failure injection sub-services (ex: chaos, latency, audit etc), opt-in and opt-out capabilities for victims, on-demand/scheduled chaos policies for admins and chaos modeling at multiple granularities i.e., cluster level/node level.
- Reproducible i.e., framework allow for repeatable experiments, dry-runs etc.
- Distributed i.e., support injections in both local & remote nodes, physical and VMs etc.
The basic idea here is that the framework take care of managing the service (specifications, injectors, detectors, analyzers, opt-in/opt-outs, scheduling and notifications etc) so that users can focus on exploring and implementing the injectors, detectors and analyzers that are relevant to their system.

Injectors -
These are components (or scripts) that actually create a failure on systems that have opted-in for chaos service. Best to keep the injectors remote to the system that is being tested. Otherwise, the failures on the target system could affect the injector capability.
An injector typically will have two parts -
- A backend that actually creates the fault (ex: shutdown a nic card) and
- A front-end that implements a pre-defined injector interface to the framework.
Another factor to consider while designing injectors is fault modes i.e.,
- Permanent faults i.e., the fault remains for the remainder of the fault injection period.
- Transient faults i.e., one-time faults and
- Intermittent faults i.e., repeating faults.
Workload Generators -
The workload generator triggers workloads (applications, benchmarks or synthetic workloads) on the target system. The workload library could be a set of policies or more simply a bunch of scripts with each script catering to triggering one type of workload.
Detectors/Data Collector -
Detectors are generally coupled with injectors i.e., an injector creates a fault and the detector tries to discover the existence of the fault and report. So these two go often hand-in-hand.
For detection purposes, wherever possible it is good to utilize time series data (ex: metrics, events etc). If the system has monitoring service (which should be the case for any enterprise system), the detectors can utilize the monitoring component. Another alternative is for detectors to make higher level service/api calls that normally get affected by the fault that is injected.
The type of the fault determines the detection mechanism. For example, fault types could be processor, memory, network, device etc. Hence the reason detectors are typically tightly coupled with injectors.
Data Analyzers -
The analyzers are responsible for collating the information and processing into an useful form. The analyzer can used to interpret the events associated with a given injector-detector combo.
If we have common analyzers then good to have a configuration file that binds injectors-detectors-analyzers and let the framework manage it.
Controller -
The brain of the system. The controller is responsible for managing the life-cycle of all components. It is responsible for understanding the policies, going thru the opt-in (opt-out) lists to include (exclude) its targets; manage fault injection schedules; determine fault injection probabilities;, remote execute relevant injectors and detectors; invoke the corresponding analyzer etc and finally send the notifications/reports.
Target/Victim -
The target (victim) is basically a target for the fault injector. The target could be a node, cluster or region. A user should provide all the details (typically - host info & credentials) necessary for the controller to inject and detect faults.
Service API/Driver -
The driver is the interface between the user and the framework. The driver will enable user to upload and manage injectors, detectors and analyzers; update policies and schedules, opt-in/opt-out etc. The driver is the bridge between the autonomous controller and the user.

Guidelines -
Some guidelines in utilizing the chaos engineering for building resilience in distributed systems.
- Define crisply what is a normal behavior (steady state) for the system.
- Best to model this steady state via measurable outputs i.e., as a collection of key metrics and range of values for each metric. For example, the metrics could be read/write latency percentiles, system throughput, error rates, failover duration percentiles etc.
- Chaos service cannot differentiate an anomalous state from steady-state unless we define crisply what is a normal state for the system.
- Reflect real-world events.
- The whole point of doing chaos engineering is to reflect inherent chaos present in the real-world environments so that the system becomes resilient.
- Any event capable of disrupting the system is a good candidate to simulate in chaos engineering. Examples - servers & disks failures, network interruptions, spikes in traffic, long delays in responses etc.
- Automate Chaos Service to run continuously
- Automate, Automate and Automate!
- Learn from customer escalations
- Customer escalations are one good source of ideas for modeling real-world events.
- POCs are another fertile ground for ideas on capturing turbulence in environment.
Chaos engineering, in my opinion is a powerful practice. It brings to forefront specifically the systemic uncertainty present in distributed systems and force an engineer to confront it. The harder it is for a chaos engineering service to disrupt the stead state of the system, the more confidence one will have in the resilience of underlying system.
References -
- Basic Concepts and Taxonomy of Dependable and Secure Computing, Algirdas Avizienis, Jean-Claude Laprie, Brian Randell, and Carl Landwehr
- A Survey on Fault Injection Techniques, Haissam Ziade, Rafic Ayoubi, and Raoul Velazco
- Fault Tolerance Techniques for Scalable Computing, Pavan B, Darius B, and Dries K
- Challenging Malicious inputs with Fault Tolerance Techniques, Bruno L. C. Ramos
- Standard error classification to support software reliability assessment, John B Bowen
- Fault Injection Framework for System Resilience Evaluation, Thomas Naughton, Wesley Bland, Geoffroy Vallée, Christian Engelmann, and Stephen L. Scott
- Fault Injection Techniques and Tools, Mei-Chen Hsueh, Timothy K. Tsai, and Ravishankar K
- Dependability and Resilience of Computing Systems, Jean-Claude Laprie.
- Principles of Chaos Engineering - http://principlesofchaos.org/
- Netflix Simian Army - https://github.com/Netflix/SimianArmy
- Pivotal Chaos Lemur - https://github.com/strepsirrhini-army/chaos-lemur
- Azure Search - https://azure.microsoft.com/en-us/blog/inside-azure-search-chaos-engineering/